OnePageResume
TL;DR: Built a full-featured resume builder that stores zero user data on any server. All resumes, work history, and personal information live exclusively in the browser via IndexedDB. AI features run through a credit system with atomic deduction (Redis optimistic locking) or BYOK (Bring Your Own Key) where API calls go directly from the browser to the provider. Cross-device sync uses WebRTC peer-to-peer connections with 6-digit OTP codes, transferring data directly between devices without touching a server.
Introduction
Resume builders are a privacy nightmare. They store your full employment history, contact info, and career trajectory on their servers. Most require accounts. Many sell your data to recruiters. And the editing experience is painful: fighting with Word formatting, manually adjusting margins to fit one page, re-entering the same work history for every application. Job seekers in competitive markets need a tool that works for them, not against them.
Design Approach
Privacy-First Architecture Every architectural decision starts with one question: does user data need to leave the browser? The answer is almost always no.
Zero-Server Storage: All state (resumes, work history, jobs, recruiters) persists in IndexedDB via Dexie.js. No accounts, no databases. BYOK API keys stay in localStorage; requests go direct to the provider.
P2P Device Sync: WebRTC via PeerJS. Desktop shows a QR code, phone scans and receives the full dataset as a single JSON blob. Bidirectional: phone generates a 6-digit OTP code, desktop enters it via a shadcn OTP input, data flows back. Custom `opr-` namespace prefix avoids PeerJS cloud collisions with auto-retry.
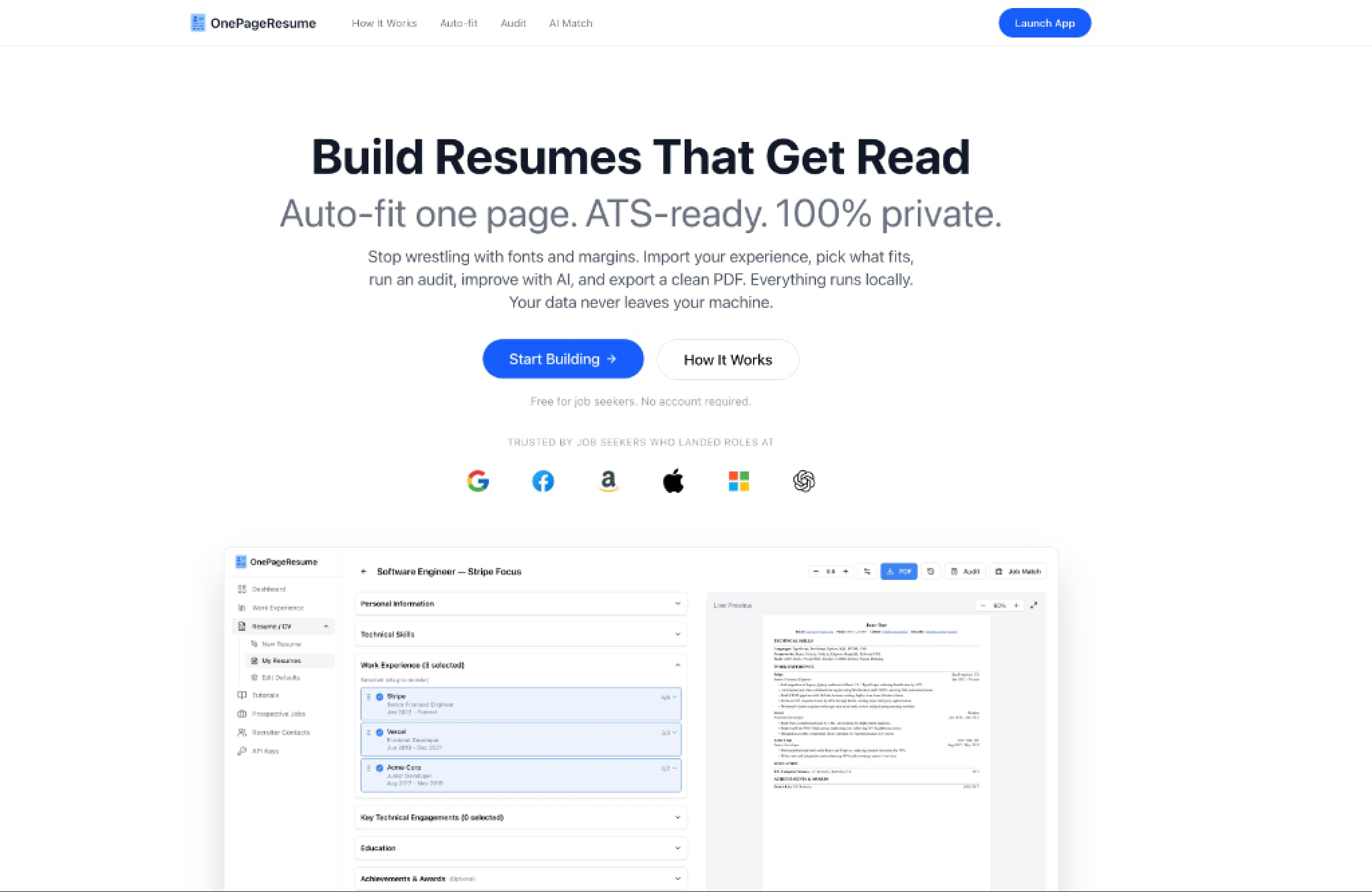
Auto-Fit, Not WYSIWYG: Editing is structured fields, not a document. The system handles typography, spacing, and PDF generation. Live overflow detection warns when content exceeds one page. Per-resume bullet toggles let users show 5 bullets on one resume and 3 on another without deleting anything. Drag-to-reorder via dnd-kit.
AI Audit Engine: Multi-pass static analysis: bullet strength scoring, vague tech reference detection ("SQL databases" → "PostgreSQL"), entity hierarchy for company prestige and career progression, LLM-powered semantic job matching.
Credit System: Redis-backed atomic deduction with optimistic locking (3-retry loop). Rate limited at 60 req/60s per license key. Stripe invoice flow for purchases.
Reusable EntitySheet Pattern: Identified a recurring UX pattern (list + slide-over sheet, explicit submit for create, 800ms debounced auto-save for edit) and extracted it into a shared component used across work experience, jobs, and recruiters.
Technical Stack
AI: Multi-provider BYOK (OpenAI, Anthropic, Gemini) + Redis-backed credit system with atomic deduction. Structured prompt engineering for job posting parsing, resume-to-JD semantic matching, and bullet rewriting. Evaluation pipeline scores bullet strength, quantification, and action verb variety across the full resume.
P2P Sync: PeerJS/WebRTC, 6-digit OTP codes, QR scanning, bidirectional transfer
PDF: Client-side generation, ATS-optimized single-column layout
Audit: Multi-pass static analysis + LLM semantic job matching
Frontend: React 18 & Tailwind CSS, featuring a custom state machine designed to handle complex branching logic and resilient data syncing on "low-end" hardware.
Data: Zero server-side storage. IndexedDB for persistence, localStorage for settings/keys. The only server-side state is a license key → credit balance mapping in Redis. All resume content, work history, and PII stays on-device.
Serverless: Two Vercel Edge Functions total: one for credit balance checks, one for proxying AI requests. The eval pipeline (bullet analysis, hallucination detection, entity hierarchy) runs entirely client-side in the browser. No server compute needed for the core product.
